
Claude writes the code. Codex tries to break it. The disagreement is the useful part.
Every developer I talk to this year asks me the same question. "You use both Claude Code and Codex. Which one is better?" It is a fair question. It is also the wrong one, and it took me a few hundred shipping sessions to understand why.
I stopped choosing. On real production work, the most reliable workflow I have found is not picking a winner. It is putting both agents on the same task and letting them pair-program: one writes, the other tries to tear it apart, and nothing ships until they have argued it out and the code actually runs.
None of this is a new idea. Long before AI, the best teams put two humans on one problem. They call it pair programming: one person drives and writes the code, the other navigates, watching and guiding and catching the bug before it ships. One moves fast. The other keeps them honest. Some of the best code I have ever shipped came out of a pair like that.
So I did not invent a workflow here. I cast an old one. Claude drives. Codex navigates. The only thing that changed is the navigator: this one never gets tired, never nods along to be polite, and is there at 2am.
I run this every day on real production work, where a quiet bug is expensive. Here is the system, why it beats a single agent, and where each tool actually pulls its weight.
Why "versus" is the wrong frame
The "versus" framing assumes these tools are interchangeable, that you slot one in and rip the other out. In practice they have different temperaments, and the difference is the whole point.
Claude Code (I run it on Opus 4.8) is a strong, fast driver. It reads a codebase quickly, holds a plan in its head, and writes code that fits the house style. Codex (GPT-5) is a sharper skeptic. When I hand it a finished diff and ask it to find what is wrong, it is unusually good at spotting the race condition, the missed edge case, the assumption nobody wrote down.
Put a generator and a critic in a room and you do not get an average of the two. You get something neither produces alone: code that has already survived a hostile review before a human ever reads it.
A generator and a critic are not competitors. They are a pair. The value is not in either one. It is in the friction between them.
The Driver
Claude Code · Opus 4.8
- Reads the repo and drafts the plan
- Writes the implementation in-style
- Holds the full task in context
- Runs the verify gate (it owns the shell)
The Skeptic
Codex · GPT-5
- Critiques the plan before any code is written
- Adversarial review of the finished diff
- Hunts race conditions, security gaps, missed requirements
- Breaks decision ties when I would otherwise stall
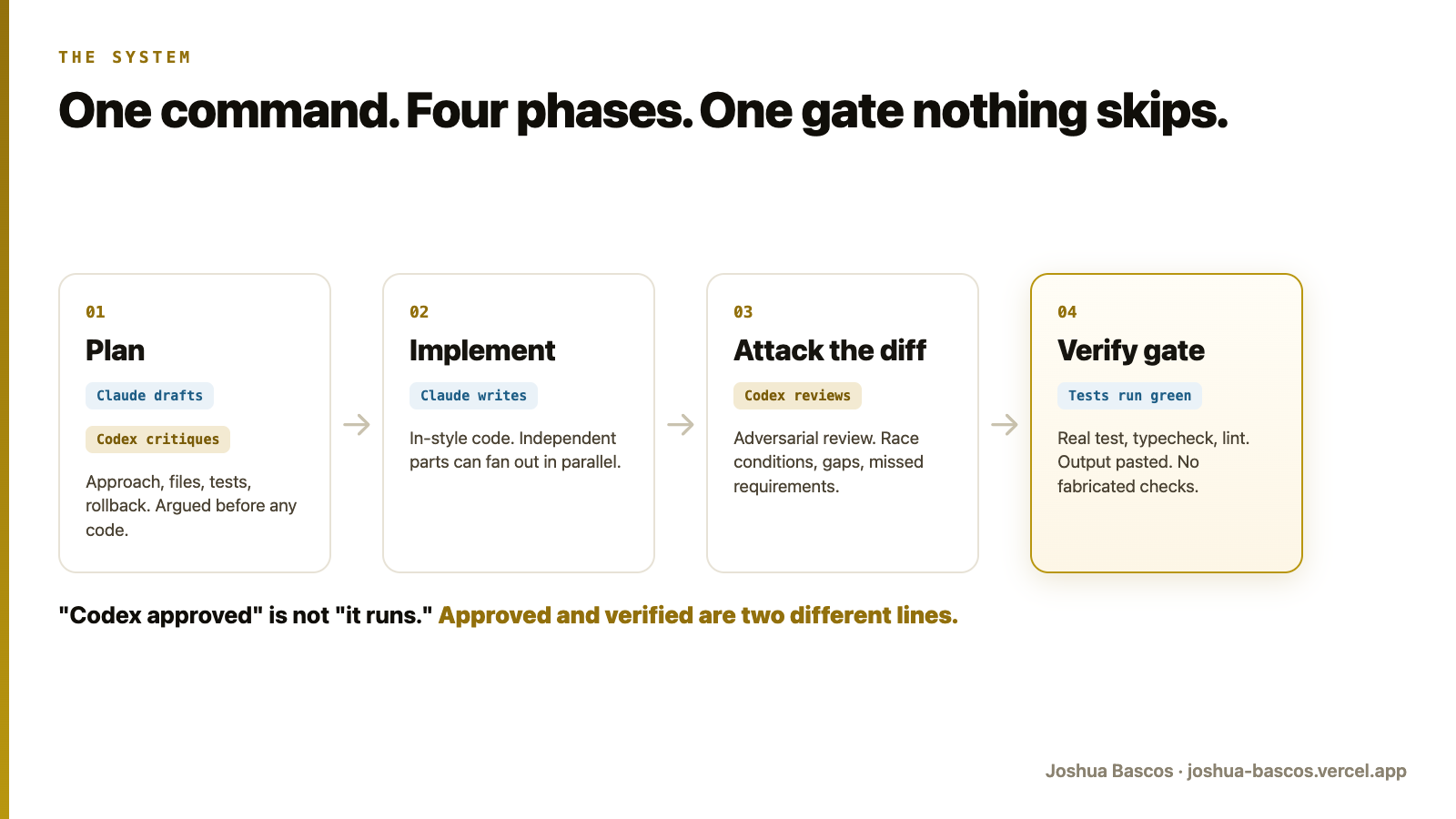
The system: one command, four phases
I wrapped the whole thing into a single command I call /duo. I type the task once, and the pair runs it to completion without bouncing every small decision back to me. It moves through four phases, and the structure is the part that matters more than the models.
How a /duo run actually flows
- Plan. Claude reads just enough of the codebase to draft a plan: files to change, approach, tests, a rollback if it is risky. Then it hands the plan to Codex with one instruction: critique this adversarially, flag what is missing. They iterate until they converge or until I have a clear, documented disagreement.
- Implement. Claude writes the code. Independent sub-tasks can go to Codex in parallel and come back as patches that get reviewed before they are applied. Nobody trusts a patch on sight.
- Adversarial review. The finished diff goes back to Codex with a blunt prompt: challenge the approach, question the tradeoffs, find the failure modes. Every real issue gets fixed. Every disagreement gets recorded with my reasoning.
- Verify gate. "Codex approved" is not "it runs." The code does not pass until the project's actual test, typecheck, and lint commands run green and the output is pasted into the report. No green check gets fabricated.
/duo run. The last one does not skip.Then it writes a short report and, just as importantly, a log. Every run drops a dated record of what the two agents disagreed on and how it resolved. That audit trail has become one of the most useful artifacts in my workflow, because six weeks later I can see not just what we built, but the argument that got us there.
The inversion: when your own budget is the bottleneck
Here is the practical wrinkle nobody writes about. I run both tools on their Max plans, which means I am managing two separate token budgets, not one. Some sessions, Claude is the scarce resource. Other sessions, it is the one with headroom.
So I built a second command, /duox, that flips the roles entirely. Claude stops driving and becomes the orchestrator. Codex does the heavy lifting: it explores the repo, drafts the plan from scratch, implements in parallel, reviews its own diff, and diagnoses the test failures. Claude only dispatches the work, applies the patches, runs verify, and writes the report.
Same discipline, opposite economics. When my Claude budget is tight and my Codex budget is full, I burn the side of the ledger that has room. The work still ships through the same four-phase gate. I am just choosing which agent pays for it.
# Same task, two economics. I pick by which budget has room. /duo → Claude drives, Codex critiques. Balanced burn. /duox → Codex does the work, Claude steers. Saves Claude tokens. # Both end at the same place: verify green + a logged record of every disagreement
Why the disagreement is the actual product
The instinct with AI tools is to chase agreement. Two models said yes, so it must be right. I had to unlearn that. The moments worth my attention are exactly the ones where the driver and the skeptic do not agree.
When Codex flags something and Claude pushes back, one of three things is true: the flag is real and we fix it, the flag is wrong and Claude explains why in writing, or the call genuinely needs a human. That third case is rare, and when it happens it lands on my desk already framed: here is the choice, here is each side, here is what is expensive to get wrong. I make a sharper decision in thirty seconds than I would have made in ten minutes of solo back-and-forth.
Agreement is cheap. The disagreements are where the bugs live, and where the real engineering decisions hide.
What it looks like on real work
This is not a toy setup. It runs against the kind of production systems where correctness is not negotiable, where a quiet bug is genuinely expensive and "it looked fine on my machine" is not a standard anyone accepts. In that context the verify gate is not bureaucracy. It is the difference between a demo and a deployment.
The pairing also composes with parallelism. Once a plan is agreed, independent pieces fan out across multiple agents at once. One recent session, with the pair coordinating the work, shipped a stack of changes in a single sitting that would have been a week of careful solo work:
Volume is not the point, though. The point is that every one of those commits went through the same gate: planned, reviewed by an adversarial peer, verified green, and logged. Speed without that discipline is just a faster way to ship bugs.
When I reach for which
I do not run the full pair on everything. That would be its own kind of waste.
My rough rules
- One clear, low-risk change (a copy fix, a small refactor): a single agent, no ceremony. The pairing overhead is not worth it.
- Anything that touches money, auth, data integrity, or migrations: the full pair, every time. This is exactly where a second set of adversarial eyes earns its cost.
- Strategy, advice, "what should I do here": neither command. There is no code to review, so the protocol is just theatre. I answer directly.
- Budget-constrained heavy work: the inversion, so the agent with token headroom does the lifting.
The meta-lesson is the one I keep coming back to. The leverage is not in finding the single best model. It is in the system you build around them: a clear plan, an adversarial review you cannot skip, a verify gate that does not lie, and a record of every argument. The models will keep getting better. The discipline is what makes them trustworthy on work that matters.
So when someone asks me "Claude Code or Codex," I have stopped answering the question. I tell them what I actually do: I use both, I make them argue, and I do not let either one declare victory until the tests are green and the disagreement is written down.
The best pair-programming partner I ever had was another person who refused to rubber-stamp my code. It turns out two AI agents, pointed at each other, can play that role surprisingly well, as long as you build the room they argue in.